Sample Data as input for Wizard
It is crucial to have a clear understanding of what data means to prevent mistakes and miscommunication while sharing data. To achieve sharing data with a clear and unambiguous understanding, communities need to express their data offering or data need using a common vocabulary. This requires communities to either possess their own vocabulary or base it on existing standards. However, this poses a significant barrier for communities to create their own vocabulary and achieve semantic interoperability in their respective domains. To overcome this hurdle, we allow users to create an initial vocabulary based upon their sample data.
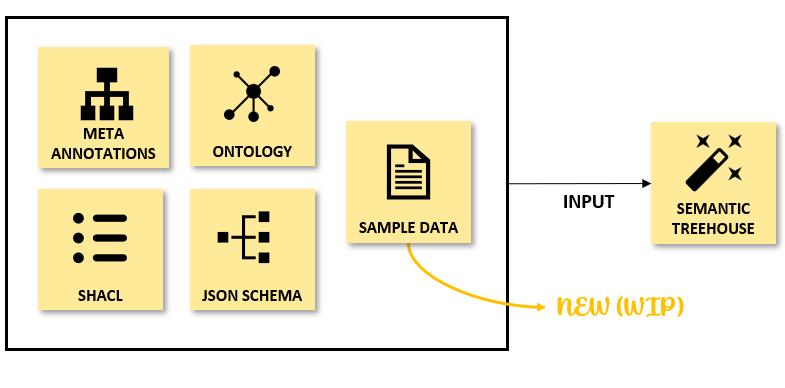
This section describes the currently supported features and limitations of our sample data input, but be aware that our sample data import effort is still under development. This section explains the supported features, some examples, and future work.
Supported Sample Data
This functionality provides communities with the opportunity to start the creation of a domain-specific language from sample data. Similar to the other inputs, this feature allows users to select a starting point before specifying their own model. In this case, users can provide a sample of their data (only CSV files are supported for now). This can be done in the first step of the wizard by either pasting the data directly into the corresponding text box or upload a CSV file. The image below illustrates the first step of the wizard, including the option for CSV import.
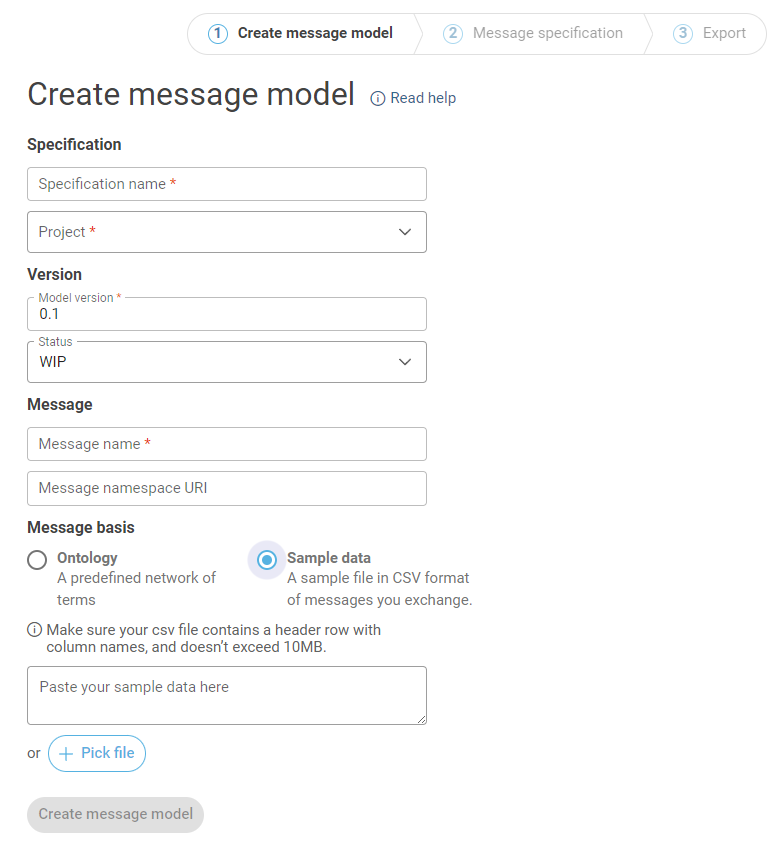
How is the message model generated?
The column names in the CSV file will become the element names in the initial message model in step 2 of the wizard. This initial vocabulary generated in the wizard can then be further developed and enriched by its creator, for example by adjusting definitions, cardinalities or specifying the range of allowed values.
Example
This section describes two very simple examples of a CSV file, and their import in Semantic Treehouse. The first example is about product data, where the second example is about personal data with some missing instances.
Example 1: A CSV with product data
The example below is a basic CSV file that Semantic Treehouse can import.
ProductID,ProductName,Brand,Category,Price,InStock,ReleaseDate,Weight
1001,Smartphone X,XYZ Electronics,Smartphones,699.99,500,2022-05-15,150g
1002,Laptop Pro,ABC Tech,Laptops,1299.99,200,2022-03-10,2.5kg
1003,Smartwatch Lite,PQR Wearables,Smartwatches,149.99,1000,2022-08-20,50g
1004,Headphones HD,AudioZone,Headphones,79.99,800,2022-06-05,250g
1005,Tablet Elite,DEF Devices,Tablets,499.99,300,2022-01-22,450g
After uploading this CSV file in the Wizard, it will present a message treeview displaying the column names as three potential sub-properties:
- Product Data
- [0..1] ProductID
- [0..1] ProductName
- [0..1] Brand
- [0..1] Category
- [0..1] Price
- [0..1] InStock
- [0..1] ReleaseDate
- [0..1] Weight
Example 2: A CSV with missing data
This example is about personal data. It is a very limited example of a CSV file, yet it missing the data about the age of John. Despite that, an initial message model will be generated with the column names as element names.
Name,Age,Occupation
John,,Engineer
Alice,32,Doctor
Eve,22,Student
After uploading this CSV file in the Wizard, it will present a message treeview displaying the column names as three potential sub-properties:
- Personal Data
- [0..1] Name
- [0..1] Age
- [0..1] Occupation
What is next?
Currently, we only support sample data in CSV files. In the future, we plan to broaden this support and allow more formats, such as sample data in XML or JSON. In addition, we are actively working on how Large Language Models can assist in predefining definitions for the column names, which are then based on an existing vocabularies. This will improve the reusability of existing vocabularies. Additionally, we aim to extract more information from the imported CSV file. In the next version, we are exploring how to predefine cardinality, definitions, and data types based on the imported CSV.
Related documentation: Please find the documentation for wizard step 1.