Vocabulary Support for Sample Data (CSV)


Semantic Treehouse is designed to maximize the reuse of common vocabularies (semantic standards) to ensure a shared understanding of the data. These vocabularies are assumed to be created through open standardization, meaning that they're created 'by the users, for the users'. Open standardization justifies what is essentially a top-down approach to interoperability: as soon as the standard is done, it is published in a central place and users are expected to comply by aligning their data to it.
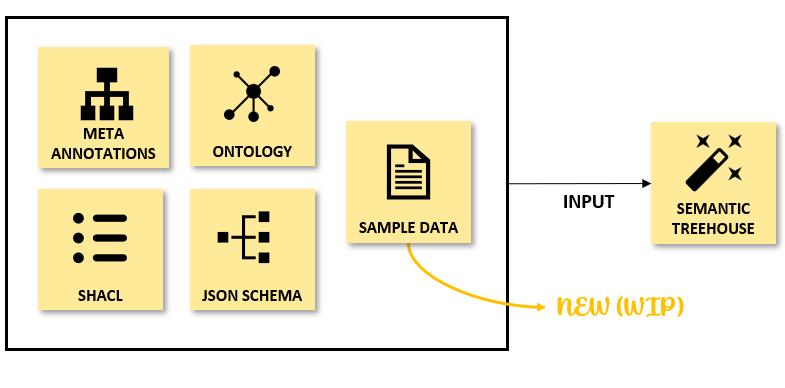
However, there are various situations that would benefit from a more 'bottom-up' approach, i.e. where the information flow is reversed. Instead of Semantic Treehouse providing information on what vocabulary to use, users provide information on the usage of their data. This need arises in situation where, for example, there's only a loosely defined community where standards are not yet formed. Or when typical users don't have the resources or knowledge to work with semantic standards and make alignments. To overcome this hurdle, Semantic Treehouse has developed a new functionality that allows users to create an initial vocabulary based on their own sample data.
Bottom-up approach
In its first iteration, users can create a vocabulary by providing a sample of their data. This sample is expected to be in CSV format. The wizard then generates an initial vocabulary based on the data fields in the sample. The user can then start the process of enriching the vocabulary, e.g. by providing definitions for each data field or cardinality constraints. It also serves as a starting point to map these data elements with concepts in common vocabulary standards, if these exist. It can also serve as a practical example to guide the direction of any open standardization process aiming to find a suitable common vocabulary. Since the direction of information flows from users to the centralized standardization effort, we refer to this approach as the bottom-up approach to semantic interoperability.
Example: A very simple CSV file
Similar to the other inputs, this concept is to upload sample data before specifying your own vocabulary in the message treeview of the wizard. For example, below is a basic CSV file that Semantic Treehouse can import. Semantic Treehouse considers the column names in the CSV file as element names in the generated vocabulary.
Name,Age,Occupation
John,55,Engineer
Alice,32,Doctor
Eve,22,Student
After uploading this CSV file in the Wizard, it will present a message treeview displaying the column names as three potential sub-properties:
- Personal Data
- [0..1] Name
- [0..1] Age
- [0..1] Occupation
What is next?
Now it is time to edit, maintain or publish this vocabulary for your own domain-specific use case. In the meantime, we are actively working on improving this feature, starting with deriving the cardinality and data types from the CSV file. Additionally, we are exploring ways to improve the reusability of vocabulary by providing a pre-defined definition of the columns based on existing vocabularies.